
Bruno Oliveira (brunoedgarero@gmail.com)
Faculty of Engineering of the University of Porto
Supervisor: Carla Teixeira Lopes, PhD (ctl@fe.up.pt)
The first stage of our work involves building a representative sample of SERP interfaces over time. After collecting this sample, our attention focused on its analysis and the automation.
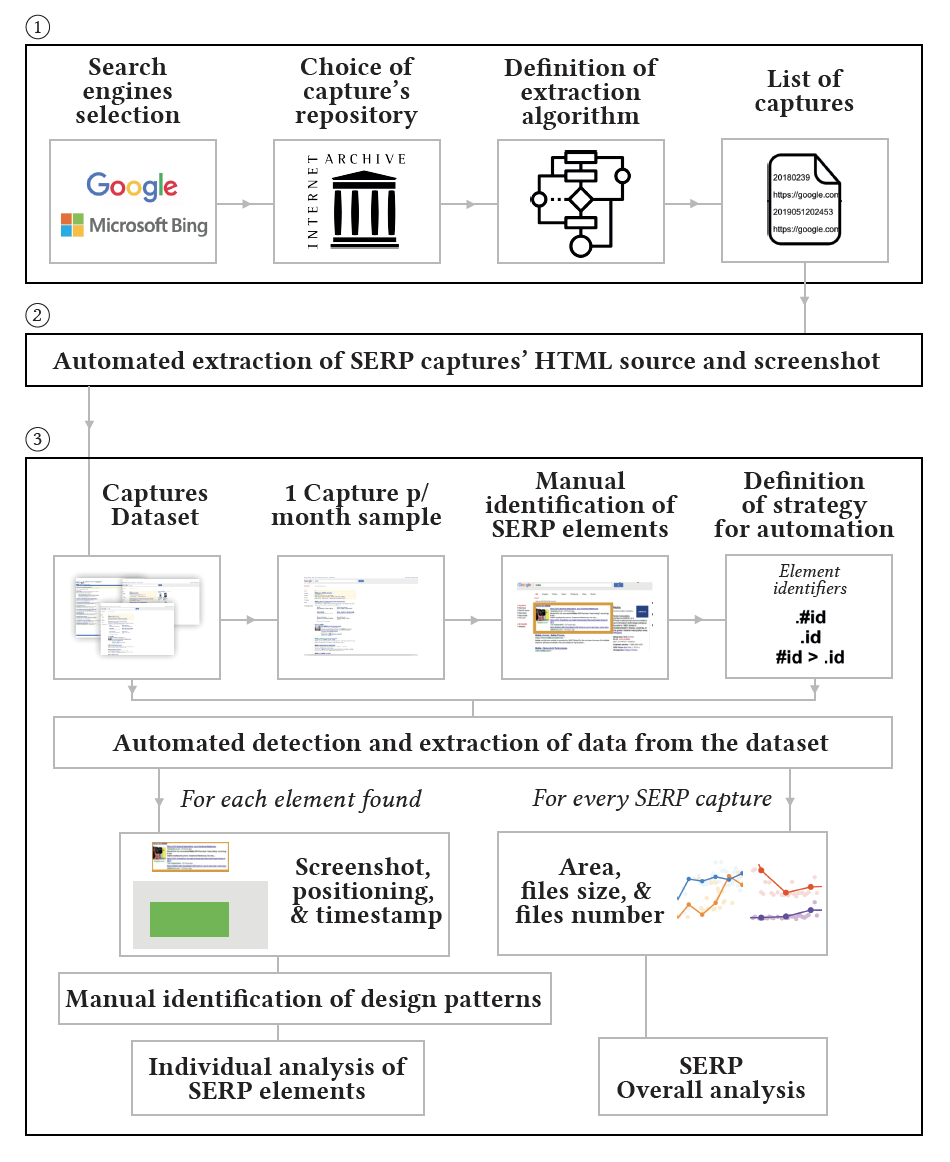
What SERP have we captured?
Being Google Search and Microsoft Bing responsible for 95% of the market share, we decided to focus our analysis on this search engine. Although Web search engines are also available on mobile platforms, their interfaces are considerably different from desktop ones. This study will address desktop versions of the first SERP exclusively, from 2000 2020.
The Internet Archive has been keeping snapshots and the respective HTML version of webpages over time. Its collection contains more than 50 billion webpages. Internet Archive provides a standalone HTTP servlet, the Wayback CDX Server API, that allows complex querying, filtering, and analysis of captures. It enables, for example, to obtain the timestamp of captures in a 14 digit format, filtering captures by date (year, month, and day) and URL. While filtering by URL, we can use a wildcard (*) at the end of the URL to specify the latter as a prefix and also receive entries that go beyond the specified URL (e.g., www.google.com/search?q=cookies*).
Using the API, we found more than 200 thousand captures of SERP during two decades. This large number of SERP and existing resource restrictions led us to devise a method to identify a smaller, yet representative, set of SERP. Initially, we collected a random sample of SERP over time, but results would retrieve captures that referred to non-usual queries, some of them with non-sense characters and most of them being strangely too restrictive. To assure SERP diversity, we have used a set of 129 most searched queries in the last 20 years, available here. These queries contain relevant terms often searched by users and, consequently, trigger features in SERP. Hence, it is highly likely that SERP interfaces derived from these queries are richer and, thus, more relevant for this study than those generated by random searches. We decided to append these queries with the ‘*’ wildcard while submitting them to the API to obtain a larger amount of captures.
Using the most searched queries, we noticed that some years had no captures. In those years, we collected all the available captures. We also noticed that the two last years had a much larger number of captures (>10 thousand). Therefore, in 2019 and 2020, we restricted the URL submitted to the API to those without queries longer than 37 char, the equivalent of 6 words, with an average length of 5 char, and spaces between them. This restriction excludes longer and more specific queries that are probably less useful to the plurality of interfaces. Please check the Dataset page.
How have we captured SERP?
We used Python and Selenium Webdriver, for browser automation, to visit each capture online, check if the capture is valid, save the HTML version, and generate a full screenshot.
Not all the captures listed by the API were considered valid, even though being labeled with an OK status code. Some are inexistent, with a contradictory message of URL not captured, and some are defective (e.g., showing incomplete interfaces without search results). To automatically assess the validity of each capture, the program tries to find an organic result, the element that cannot lack in a SERP. Captures from other SERP tabs other than the general first page, identified in the Google's case with the substring “tbm” in the URL, were also discarded for being outside of this work’s scope. A timeout exception is raised after 6 seconds, which means the program will skip that capture, which was the time that was empirically considered sufficient for a valid capture to be fully loaded. Before downloading the page, we still have to remove graphical elements from Internet Archive, such as its information and donation bars. Some captures present other distracting banners, overlapping parts of the interface, such as the ones related to cookie consent. The ones we were able to identify have been incorporated in the removal process.
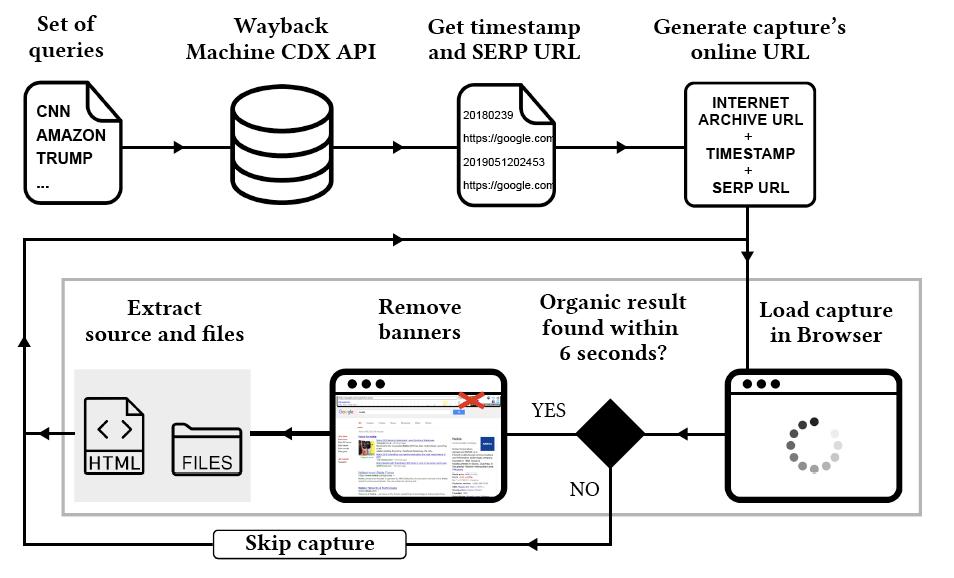
The existing methods can only access the webpage source code. Thus, to download the source code and the respective files, we used an external library pyautogui to simulate the keyboard keys to trigger the browser’s save function.
The process concludes with the generation of full-height screenshots of every HTML version, opened in another browser instance, in headless mode. Because SERP are responsive to the screen’s size, we produced screenshots considering the most popular screen size at the time of the capture. We only considered the width measure because SERP height is highly variable. According to screen size usage throughout the years, we used the following browser widths: 800px (2000-2002), 1024px (2003-2011), 1366px (2012-2019), 1920px (2020).
The dataset contains all the extracted captures. Each capture is represented by a screenshot, an HTML file, and a files’ folder. We concatenate the initial of the search engine (G/B) with the capture’s timestamp for file naming. The filename ends with a sequential integer “-N” if the timestamp is repeated. For example, ‘G20070330145203-1’ identifies a second capture from Google by March 30, 2007. The first is identified by ‘G20070330145203’.
How have we analyzed SERP?
The analysis process included two main stages. In the first, we manually analyzed a set of screenshots to identify SERP elements. We selected the capture with the most features for each month by manually looking at the screenshots of that month’s captures. In a second stage, we automated the detection of these elements over time, allowing the exploration of a larger number of cases. We have analyzed the HTML code of each element found in the previous stage, searching for identifiers. Since elements’ code was frequently changing, it was not possible to list every single identifier that elements might have had, but all the identifiers encountered were logged and are listed in every Element page. Element identifiers consist of HTML classes, ids, tags or a combination of these using CSS selectors (e.g., featured snippets: ‘#knocube’ or ‘#res .hp-xpdbox’).
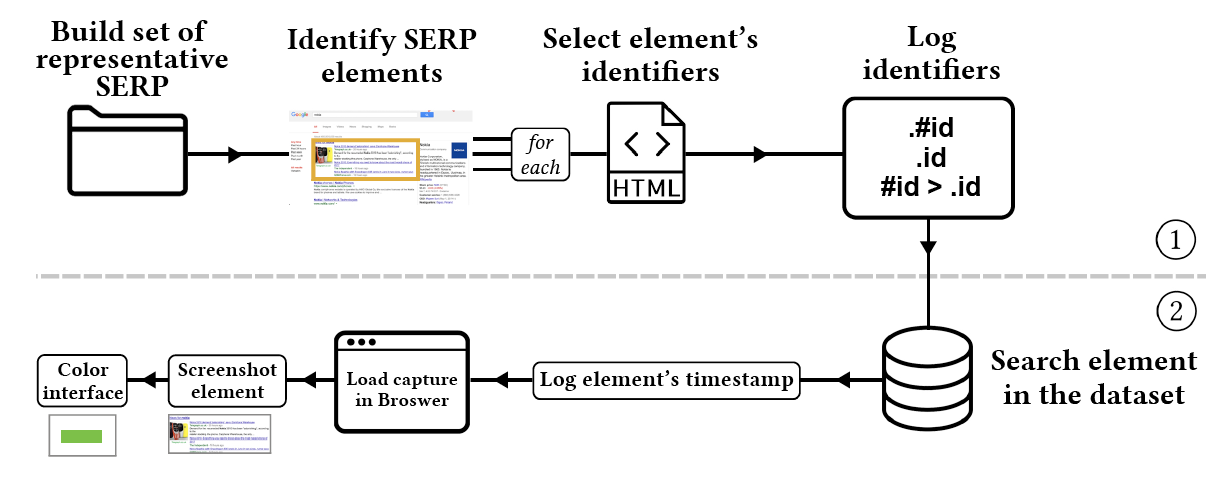
Finding an element with these identifiers triggers a function that receives the coordinates of the element’s upper-left corner, and its width and height. This function locates the element, generates and saves an image of it in the element’s folder. The capture’s timestamp is stored in a log file that keeps a record of the time of the element’s appearance. Due to the large scale of the dataset, we restricted the image generation to 15 images per month. However, it is possible to change the approach and skip images generation, just to store all the elements’ timestamps in a file. No limit of captures per month is needed as the computation permits a full dataset scan in an acceptable time.
Another automation was applied to coloring interfaces according to the position of element categories. Following a similar procedure, the list of identifiers allowed to automatically detect and color targeted areas of the webpage. We used Python, Selenium Webdriver, and BeautifulSoup to scrape every single HTML capture in colored phases to identify and generate transparency-colored images. Due to the size of the dataset, we imposed a limit of 15 elements/captures per month, as in the extraction of elements’ images. The end result of each category is an image that overlays all the individual images from single captures. The high level of transparency will enhance the most common areas at the end while leaving the others almost unnoticeable. The overlaying process uses the upper-left corner as the reference for image alignment. However, the navigation & user inputs category includes elements in and next to the footer, but these common areas were not evident in the result due to how variable the height of the captures can be. In this case, to reproduce the overlapping of every bottom of the interface, the algorithm had to consider a height value of N, cropping the results from the initial pixel (original height minus N) to the lower-left corner (original height), maintaining the original width. Thus, the end result is trimmed at the middle and should be seen as two separate results.